TCP/IP相关的基础知识、术语已经在之前的文章中介绍过了。这里主要介绍三次握手、四次挥手、缓冲区、拥塞控制中各种状态的意义以及相关内核参数的配置。
一、三次握手
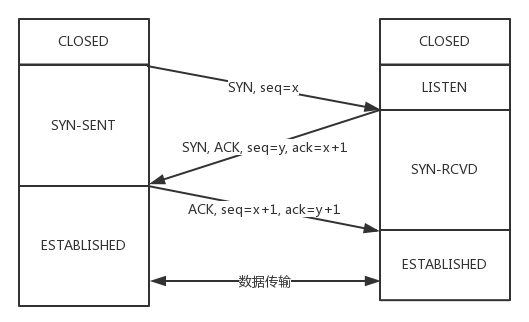
1.1 三次握手流程
1)当客户端调用connect函数后,内核会向服务器发送SYN+序号,并进入SYN_SEND状态。
2)服务器内核收到SYN消息后,会建立一条连接并放入半连接队列,回复SYN+ACK,进入SYN_RCVD。
3)客户端收到SYN+ACK后,回复ACK,进入ESTABLISHD状态。
4)服务器收到ACK后,把连接从半连接队列移到accept队列中,进入ESTABLISHD状态。
1.2 三次握手参数
1.1 半连接队列
在step2时若服务器半连接队列已经满,则请求建立新连接的SYN会被丢弃。可通过如下方式查看。
1 | netstat -s | grep "SYNs to LISTEN"#被丢弃的SYN数量 |
可以通过内核参数调大半连接队列大小
1 | net.ipv4.tcp_max_syn_backlog = 1024 #半连接队列大小(累计值) |
如果想在半连接队列已满的情况下继续建立连接可通过开启syncookies实现,syncookies的原理是服务器收到syn时不使用半连接队列,在服务器发送SYN+ACK时生成一个验证码,客户端回复ACK时再验证,如果验证通过则连接成功。正常情况下半连接队列是不会满的,为了预防SYN泛洪攻击,可以把synccookies改为半连接队列满后再启动。
1 | net.ipv4.tcp_syncookies = 1 #0关闭,1半连接队列满后启用,2无条件启用 |
1.2 重发SYN+ACK
若服务器发送SYN+ACK后一段时间内没收到ACK则会重发SYN+ACK,我们可以根据情况设置重发次数
1 | net.ipv4.tcp_synack_retries = 5 #第一次到第5次分别时间间隔为 1s, 2s, 4s, 8s, 16s,32s |
1.3 Accept队列
当服务器收到ACK后(step4),会把连接从半连接队列移除,加入到accept队列中,等待用户进程调用accept,若此时accept队列已满,则会造成accept队列溢出,此连接被丢弃。可通过如下参数配置
1 | net.ipv4.tcp_abort_on_overflow = 0 |
当此参数为0时:若accept队列溢出当前accept会被丢弃,但不会从半连接队列中移除,因为客户端发完ACK后已经进入ESTABLISH状态,在偿试向服务器发送消息时,如果多次发送失败,则会重新发送ACK,此时如果服务器已经退回半连接状态则可以重新偿试建立连接,如果这时候accept队列有空位,则连接建立成功。
当此参数为1时:则accept队列满后直接发送RST到客户端,关闭连接。通常情况下,设为0即可,如果非常肯定经常会益出,则设置为1,当然也可以直接调大半连接队列
1 | net.core.somaxconn = 128 |
通过如下命令可以查看溢出情况
1 | netstat -s | grep "listen queue" |
当下各监听端口上的 accept 队列长度可以通过ss -ltn命令查看
1.4 TFO
通常情况下,我们需要在三次握手结束后才能发送数据。但开启TFO使得我们可以在第1次握手时就能发送数据,TFO是这样实现的:第一次建立连接时走正常的TCP三次握手流程,服务器会把客户端ip地址加密作为Cookie携带在SYN+ACK包中发给客户端。下次客户端再连接服务器时,就可以在第1次握手时发送数据了,但第1次握手只能使用sendto或sendmsg(因为send必须在连接建立后才能使用)。服务器收到sendto后会验证Cookie若通过,除了通知用户进程外还会向客户端发送SYN+ACK,虽然客户端会回复ACK但服务器丢弃它。若要开启此功能需要客户端和服务器同时支持,配置如下:
1 | net.ipv4.tcp_fastopen = 3 #按比特位控制,第1位为1表示作为客户端时支持,第2位为1表示作为服务器时支持,第1、2位同时为1表示作为客户端和服务器时都支持 |
二、四次挥手
断开连接的方式大概分为2种:直接发送RST标志位和四次挥手。正常情况下内核会通过四次挥手来关闭连接,非正常情况(比如:进程挂掉,对方端口不能访问)内核会通过发送RST标志位来关闭连接,但通过RST关闭连接不是绝对安全的(假如:进程A和进程B建立了连接,进程A突然挂了,此时进程B向进程A发送数据,内核会向进程B发送RST,如果RST在网络中出现了延迟,A已经完成了重启并和B重新建立了连接,此时RST到达B,B会意外关闭连接)
1.1 四次挥手的流程
1)主动方调用close或shutdown后,内核向被动关闭方发送标志位FIN和序号。主动关闭方状态切换为FIN-WAIT1,并进入半关闭状态。若通过close关闭的连接,则当前连接变成孤儿连接,内核会丢弃被动关闭方发来的数据,主动关闭方通过netstat -p查看时进程名为空。
2)被动方收到FIN+序号,回复ACK、序号+1,被动关闭方状态切换为CLOSE_WAIT。如果主动关闭方是通过shutdown关闭连接,被动关闭方在CLOSE_WAIT状态下允许向主动关闭方继续发送消息;若主动关闭方通过close关闭的连接,则不会向主关闭方发送数据。
3) 主动关闭方收到ACK、序号+1,状态切换为FIN_WAIT2,如果step1是调用shutdown此时主动关闭方的发送通道正式关闭。
4)被动关闭方发送FIN和序号,状态切换为LAST_ACK。
5)主动关闭方收到FIN和序号,并回复ACK、序号+1,状态切换为WAIT_TIME。主动关闭方会在WAIT_TIME状态下等待2MSL(Linux下为60s,等待2MSL的原因在之前的文章中已经说过)后进入CLOSED状态。
6)被动关闭方收到ACK,进入CLOSED状态。
1.2 四次挥手参数
1.1 重发FIN
挥手流程step1发送FIN一段时间后,没收到ACK时会重发FIN消息,重发次数为:
1 | net.ipv4.tcp_orphan_retries = 0 #0为默认值,表示重新发8次,达到最大重发次数后,依然没收到ACK则会直接关闭连接 |
1.2 孤儿连接数量
主动关闭方调用close到成功关闭前,这个连接都属于孤儿连接。如果主动关闭方同时关闭了大量连接,这会造成很多孤儿连接。如果这是正常操作,则可以通过如下参数调整最大孤儿连接数量,超出数量后新增加的孤儿连接内核会通过发送RST关闭掉。
1 | net.ipv4.tcp_max_orphans = 16384 |
1.3 FIN超时
孤儿连接处于FIN-WAIT2时,不应该等待太久,因为它不需要接收来自被动关闭方的数据。默认值为60s(2MSL)
1 | net.ipv4.tcp_fin_timeout = 60 |
1.4 TIME_WAIT连接数量
当主动关闭方进入TIME_WAIT状态后会等待2MSL,可以通过参数来调整最大允许处于TIME_WAIT的连接数。当数量超过配置值后,新关闭的连接将不会进入TIME_WAIT状态。并在/var/log/message中输出kernel TCP time wait bucket table overflow
1 | net.ipv4.tcp_max_tw_buckets = 5000 #TIME_WAIT最大连接数 |
1.5 重用TIME_WAIT端口
当存在大量状态为TIME_WAIT的连接时,若想允当前机器的进程作为客户端发起连接请求并在安全情况下复用TIME_WAIT状态连接的端口,可通过如下参数配置。
1 | net.ipv4.tcp_tw_reuse = 1 |
三、缓冲区
1.1发送和接收流程
1)应用程序调用send函数往发送缓冲区中写入数据,发送缓冲区满后调用send将被阻塞。
2)发送方内核 对数据合并或分片并根据网络状况、接收方当前接收窗口可用大小把发送缓冲区中的数据通过网络发送到接收方。
3)接收方收到数据后,把数据拷贝到接收缓冲区,通知应用程序可读,并判断是否立即回复ACK。应用程序读取数据后,释放相应的接收缓冲区,并通过ACK把窗口大小同步给发送方。
4)发送方收到ACK后,删除已经确认的数据,释放相应的发送缓冲区。
网络时延积(BDP):BDP=网络带宽 * 网络延迟,当已发送但未确认的数据>BDP时继续发送数据就可能导致丢包;当已发送但未确认的数据<BDP时则跑不满带宽。由于网络状况是动态变化的,网络延迟需要反复测量再估算出一个相对准确的值。
1.2相关参数
从发送数据流程可以看出,发送缓冲区、接收缓冲区、BDP是影响传输速度的关键;BDP主要受网络环境影响,我们不能改变。而发送缓冲区和接收缓冲区可以通过socket参数SO_SNDBUF和SO_RCVBUF配置固定值。但固定值在大部分情况下显得不合理,因为网络状况、内存是动态变化的。设置太大网络情况不好会浪费内存;设置太小网络情况转好时,不能发挥高速网络的优势,所以大部分情况下会配置成动态调整即可。若同时设置了固定缓冲区大小和动态缓冲区大小,内核会采用固定大小。
1.1 发送缓冲区
动态发送缓冲区有3个值,第1个值表示发送缓冲区的最小值,第2个表示默认值,第3个为最大值。内核会根据实际需求(比如:当前内存情况、发送数据量)在值1和值3之间动态调整。
1 | net.ipv4.tcp_wmem = 4096 16384 4194304 |
1.2 接收缓冲区
接收缓冲区也可以配置成内核自动调整,但情况有些不同。
参数1:是否开启接收缓冲区动态调整
1 | net.ipv4.tcp_moderate_rcvbuf = 1 |
参数2:动态调整的触发条件,当TCP使用的内存<第1个值时不自动调整(使用默认),当在第2、第3个值之间时自动调整接收缓冲区大小,大于第3个值时不再为TCP分配内存,故不能建立新连接。
1 | net.ipv4.tcp_mem = 88560 118080 177120 #单位(页:4k) |
参数3:接收缓冲区动态调整大小,第1个值表示接收缓冲区的最小值,第2个表示默认值,第3个为最大值。当TCP使用的内存小于tcp_mem第1个值时tcp_rmem使用默认值,TCP使用的内存在tcp_mem第2个值和第3个值之间时,内核会在tcp_rmem的最小值和最大值之间动态调整。
1 | net.ipv4.tcp_rmem = 4096 87380 6291456 |
四、拥塞控制
若在不考虑拥塞,发送窗口(swnd)的大小等于接收窗口(rwnd)的大小,考虑网络拥塞后,发送窗口大小=min(接收窗口,拥塞窗口(cwnd))。 cwnd的大小可通过如下命令查看
1 | ss -nli|fgrep cwnd #linux默认为10 MSS,建立连接后,第一个RTT就可发10 MSS数据,如果默认为1发送10MSS的数据则需要4个RTT。 |
可通过如下命令修改cwnd默认值
1 | ip route | while read r; do |
1.1 拥塞的判定
1)如果一个包在指定时间内没收到ACK,则可以断定网络出现了拥塞;
2)拥塞窗口的增长到达了慢启动阈值 ssthresh,也就是之前发现网络拥塞时的窗口大小;
3)收到重复的ACK报文:假如接收方期待收到的包序号是3,但实际收到的包序号>3,则会重复发送ACK3。
1.2 拥塞算法选择
可以通过如下命令查看系统支持的拥塞控制算法
1 | net.ipv4.tcp_available_congestion_control = cubic reno #bbr算法需要linux内核版本>4.9 |
配置OS当前使用的拥塞控制算法
1 | net.ipv4.tcp_congestion_control = bbr |
1.3 传统网络拥塞算法
传统的拥塞控制算法cubic、reno主要是通过丢包来判断网络是否出现了拥塞,链路中的每个路由器都有自己的缓存,当BDP使用完后,后续的包就会进入路由器的缓存,此时网络开始出现卡顿,RTT开始明显上升,当缓存用完后,后续的包就会被丢弃,传统的拥塞控制算法检查到丢包就会启动拥塞控制,但此时网络已经出现了严重的拥塞。
(可能由于历史原因以前的路由器缓存比较小,当出现丢包时,启动拥塞并没有明显的问题;但现在路由器的缓存越来越大,丢包时再启动拥塞控制可能会带来很大的时延。)下图描述了慢启动、拥塞控制的整个过程。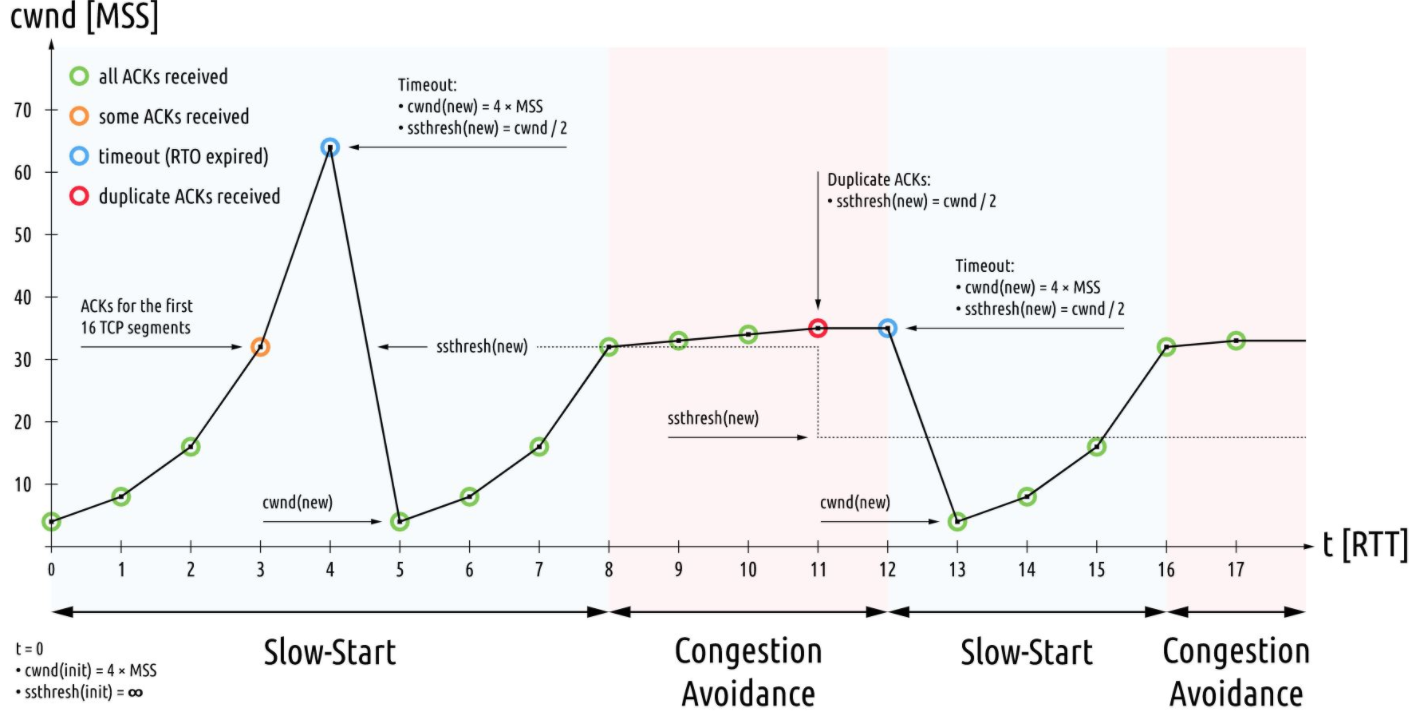
1)慢启动时每收到一个ACK,cwnd+1,直到cwnd达到慢启动门限ssthresh,此时cwnd退出指数变为线性增长每经过一个RTT,cwnd+1。
2)当丢包发生后,ssthresh降为原来的一半,cwnd重置为1。(丢包分两种情况:1.重复ACK,若收到重复ACK 3次则ssthresh和cwnd降为cwnd的一半(有丢包现象,但情况不严重); 2.包出现RTO则说明网络已经很糟糕了,cwnd直接降为初始值,ssthresh降为原来一半。)
3)当cwnd < ssthresh时,继续慢启动流程。
4)重复1 ~ 3直到数据发送完毕。
1.4 基于测量的网络拥塞算法
传统的拥塞控制算法缺点在于:发生丢包时才启动拥塞控制,此时路由器缓存已被耗尽,网络变得非常拥堵。BBR算法是基于测量的网络拥塞算法代表,它主要通过物理链路时延最小值(TRprop)和瓶颈带宽最大值(BtlBw)来确定网络是否拥塞。
TPprop:RTT由包在链路中传输的物理时间、路由器缓存排队时间、ACK延迟确认时间组成。我们只需要测得在不使用缓存情况下RTT的最小值即TPprop。
BtlBw:当发送方收到一个ACK时,可以计算出该包的RTT和这段时间内飞行中的报文字节数。speed_rate = delta_delivered/delta_t, BtlBw = max(speed_rate)。
BDP: TPprop * BtlBw,当飞行中的报文大于BDP时,开始使用路由器缓存。此时即拥塞控制的最佳点,下图中第一条竖线的位置。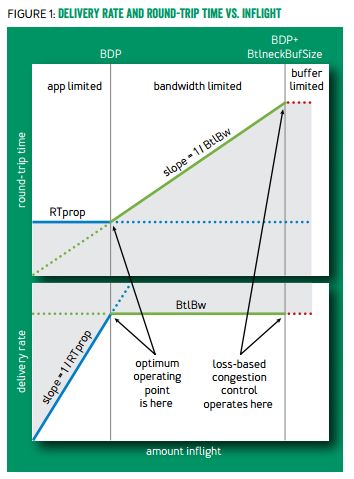
由于测量RTprop需要保证此时未使用路由器缓存,而测量BtlBw的方法是在RTT不变的情况下增加发送数据量直至RTT增长,此时会占用一些路由器缓存。所以TRprop和BtlBw不能同时测得,由于网络状况是时时变化的。BBR会定时交替测试最新的TRprop和BtlBw。